以太坊交易树和收据树知识点
ETH 交易树和收据树:知识点总览
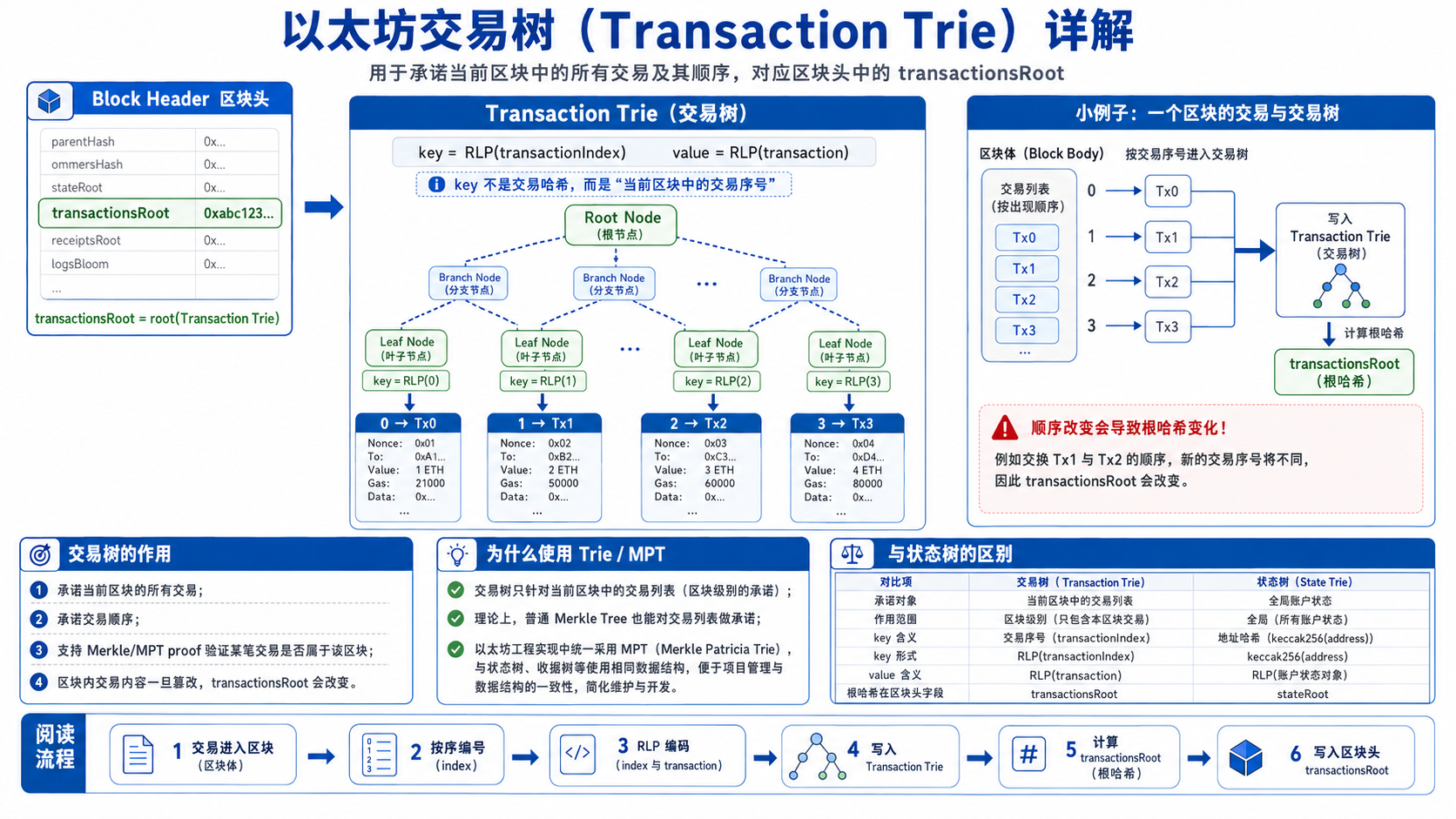
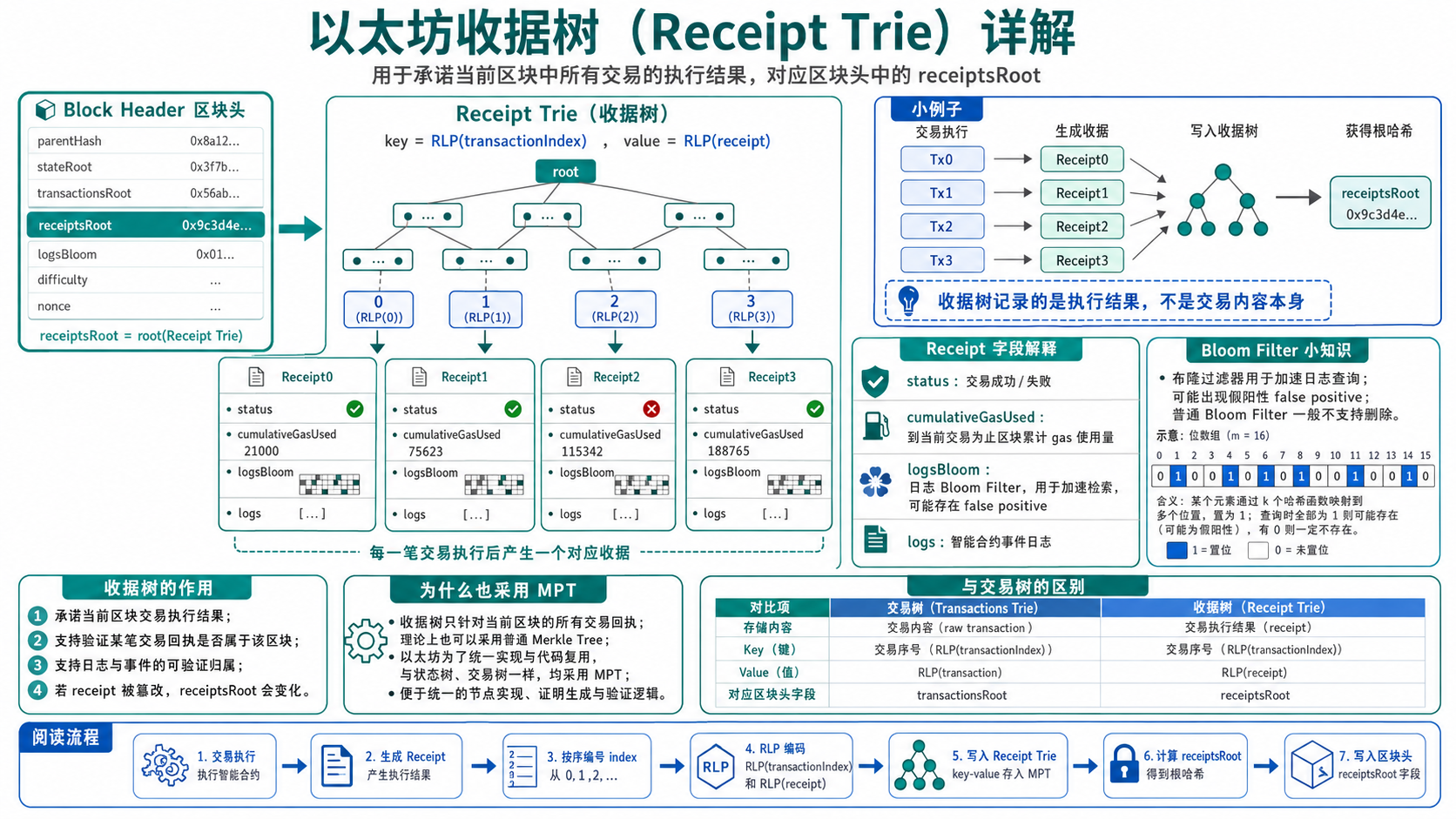
核心一句话:交易树承诺当前区块里的交易内容和顺序,收据树承诺这些交易执行后的结果。它们的根分别是
transactionsRoot和receiptsRoot,都会写入区块头。
这一篇接着状态树展开。状态树回答“执行后世界状态是什么”,交易树回答“这个区块有哪些交易”,收据树回答“这些交易执行出了什么结果”。
1. 先背下来的核心结论
以太坊区块头里和本专题最相关的三个根是:
1 | stateRoot |
它们分别表示:
1 | stateRoot -> 区块执行完成后的全局状态 |
交易树和收据树都是按交易在区块中的序号索引:
1 | key = RLP(transactionIndex) |
每笔交易执行后都会产生一个收据,所以交易和收据在 index 上一一对应。
2. 核心考点
交易树和收据树通常考四类能力。
第一类:能区分 stateRoot、transactionsRoot、receiptsRoot 的含义。
第二类:知道交易树承诺交易内容和顺序,收据树承诺执行结果和日志。
第三类:能解释为什么交易顺序影响最终状态。
第四类:能把 Receipt、logs、Bloom Filter、事件查询和区块浏览器展示联系起来。
继续深入时,可以追问:交易树和收据树为什么也用 MPT?它们和状态树的 MPT 必要性是否一样?
3. 三个根在区块里的位置
以太坊区块可以简化为:
1 | Block |
transactionsRoot 和区块体中的交易列表直接相关。只要某笔交易内容变化,或者交易顺序变化,交易树根都会变化。
receiptsRoot 和交易执行后的收据列表相关。只要某笔交易的执行状态、gas 使用、日志发生变化,收据树根都会变化。
stateRoot 是执行所有交易后的全局状态根。它不是当前区块交易列表的根,而是执行完成后的世界状态承诺。
4. 交易树 Transaction Trie
交易树用于组织当前区块中的所有交易,对应区块头里的:
1 | transactionsRoot |
交易树的逻辑结构是:
1 | 0 -> Tx0 |
工程上可以表示为:
1 | key = RLP(transactionIndex) |
交易树承诺两件事。
第一,当前区块包含哪些交易。任何交易内容被篡改,transactionsRoot 都会不匹配。
第二,这些交易的顺序是什么。以太坊交易顺序影响状态转移,所以顺序本身也必须被承诺。
5. 为什么交易顺序很重要
以太坊是状态机:
1 | 旧状态 + 有序交易序列 -> 新状态 |
如果同一组交易换一个顺序,最终状态可能完全不同。
例如:
1 | Tx0:Alice 给 Bob 转 5 ETH |
如果先转账导致 Alice 余额不足,那么后续合约调用可能失败。反过来先调用合约,结果可能不同。
nonce 也依赖顺序。同一个账户的交易必须按 nonce 顺序执行,否则交易有效性会改变。
所以交易树不是只承诺“集合”,而是承诺“有序列表”。
6. 收据树 Receipt Trie
收据树用于组织当前区块中每笔交易执行后的结果,对应区块头里的:
1 | receiptsRoot |
每笔交易执行完成后都会产生一个 Receipt。简化结构如下:
1 | Receipt |
status 表示交易执行是否成功。通常 1 表示成功,0 表示失败。
cumulativeGasUsed 表示当前区块中从第一笔交易执行到这笔交易为止累计使用的 gas。
logsBloom 是日志布隆过滤器,用于加速事件查询。
logs 是合约执行过程中产生的事件日志。
7. 交易和收据的一一对应
交易树和收据树都按交易 index 建 key:
1 | Transaction Trie |
这种对应关系很重要。它让验证者可以证明:某个区块中的第 N 笔交易,确实产生了第 N 个执行收据。
交易树关注输入,收据树关注输出。
1 | Tx_i -> EVM 执行 -> Receipt_i |
如果有人修改交易日志、状态码或 gas 统计,receiptsRoot 就会变化。
8. 收据中的 logs 和事件
智能合约可以通过 event 产生日志。例如 ERC-20 转账常见事件:
1 | event Transfer(address indexed from, address indexed to, uint256 value); |
一次 USDT 转账可能产生一条 Transfer 日志:
1 | Log |
区块浏览器中看到的 ERC-20 转账记录,很多时候就是从交易收据的 logs 解析出来的。
所以收据树不只证明“交易成功或失败”,还承诺事件日志确实由某笔交易产生,并被记录在某个区块中。
9. Bloom Filter 的考点
以太坊使用 Bloom Filter 加速日志查询。它是一种空间效率高的概率型数据结构。
Bloom Filter 判断的是:
1 | 某个元素是否可能存在于集合中 |
它有两个关键性质:
1 | 判断不存在 -> 一定不存在 |
Bloom Filter 可能出现 false positive,也就是假阳性。它说“可能存在”,但实际检查 logs 后发现不存在。
普通 Bloom Filter 不会出现 false negative。只要元素真的存在,它不会判断为不存在。
10. 为什么普通 Bloom Filter 不支持删除
Bloom Filter 底层通常是 bit array。插入元素时,会通过多个哈希函数把多个 bit 置为 1。
多个元素可能共享同一个 bit。如果删除某个元素时直接把 bit 清零,可能破坏另一个元素的存在性判断。
例如 A 和 B 都使用 bit[8]。删除 A 时把 bit[8] 清零,就可能让 B 被误判为不存在。
这会产生 false negative,而普通 Bloom Filter 的设计目标就是避免 false negative。
如果需要删除,可以使用 Counting Bloom Filter,但会增加存储成本和实现复杂度。
11. 为什么交易树和收据树也用 MPT
状态树、交易树、收据树都使用 trie 风格结构,但必要性不同。
状态树是全局、长期、动态更新的键值状态:
1 | address -> account state |
它必须支持查找、更新、证明、回滚和不存在性证明,因此非常适合 MPT。
交易树和收据树只属于当前区块,key 是连续的交易序号。理论上,它们也可以用普通 Merkle Tree 完成承诺和证明。
以太坊统一使用 MPT 风格,更多是工程统一:编码、节点结构、根哈希计算和证明机制可以复用。
这里要注意这句话:真正“非 MPT 不可”的主要是状态树,交易树和收据树使用 MPT 更偏工程一致性。
12. 三棵树对比表
| 树 | 区块头字段 | 范围 | key | value | 是否跨区块持续演进 |
|---|---|---|---|---|---|
| 状态树 | stateRoot |
全局账户状态 | keccak256(address) |
RLP(account state) |
是 |
| 交易树 | transactionsRoot |
当前区块交易 | RLP(txIndex) |
RLP(transaction) |
否 |
| 收据树 | receiptsRoot |
当前区块收据 | RLP(txIndex) |
RLP(receipt) |
否 |
状态树回答:
1 | 执行完成后,世界状态是什么? |
交易树回答:
1 | 这个区块包含哪些交易,顺序是什么? |
收据树回答:
1 | 这些交易执行后产生了什么结果? |
13. 以太坊是交易驱动的确定性状态机
以太坊可以抽象为:
1 | State_N + Block_N 中的有序交易序列 -> State_N+1 |
也可以写成:
1 | S_{t+1} = Apply(Tx_1, Tx_2, ..., Tx_n, S_t) |
所有节点从相同前置状态开始,按相同顺序执行相同交易,必须得到相同的新状态和相同的 stateRoot。
这就是状态转移确定性。如果合约执行依赖不确定外部信息,不同节点就可能得到不同结果,无法达成共识。
所以智能合约不能直接调用普通互联网 API、读取链下随机数或取本地系统时间。
14. BTC 也可以看成状态机吗
可以。比特币的状态可以理解为当前 UTXO Set。
一笔 BTC 交易会消耗旧 UTXO,并产生新 UTXO:
1 | UTXO Set_old + Transaction -> UTXO Set_new |
以太坊和比特币的差异在状态内容。
1 | BTC:UTXO 状态机 |
以太坊状态更复杂,因为它包含账户余额、nonce、合约代码和合约存储。
15. 为什么不能只保存当前区块涉及账户
一个常见问题是:每个区块只保存当前交易涉及账户状态,是否可以替代全局状态树?
答案是不行,或者至少非常低效。
如果 Alice 很久没有交易,查询 Alice 当前余额时,节点可能需要从最新区块一直向前追溯,直到找到 Alice 最后一次出现。
判断账户不存在也会很难。当前区块没有某个账户,可能是它不存在,也可能只是该区块没有用到它。
以太坊需要快速验证交易:
1 | 账户是否存在 |
这些能力要求每个区块的 stateRoot 承诺完整全局状态,而不是只承诺局部状态差分。
16. 完整执行流程
可以把一个区块的执行过程串成下面这条线:
1 | 1. 节点读取区块交易列表 |
验证区块时,节点不仅要看交易列表,也要重新执行交易,确认最终得到的 stateRoot、transactionsRoot 和 receiptsRoot 与区块头一致。
17. 高频问答
Q1:交易树保存什么?
保存当前区块中的交易列表。key 是交易在区块中的 index,value 是交易的 RLP 编码。
Q2:交易树为什么要承诺顺序?
以太坊是状态机,交易顺序会影响 nonce、余额、合约执行和最终状态。顺序不同,stateRoot 可能不同。
Q3:收据树保存什么?
保存当前区块中每笔交易执行后的收据,包括状态码、累计 gas、logsBloom 和 logs。
Q4:logs 有什么用?
logs 记录合约事件。区块浏览器和应用后端常通过解析 logs 展示 ERC-20 转账、NFT Transfer 等事件。
Q5:Bloom Filter 为什么有用?
它可以快速排除不相关区块或收据。判断不存在时一定不存在;判断可能存在时还要继续检查 logs。
Q6:交易树和收据树为什么也用 MPT?
主要是工程统一。它们只针对单个区块,key 是连续 index,理论上普通 Merkle Tree 也能完成承诺功能。
Q7:状态树和交易树最大的区别是什么?
状态树是跨区块持续演进的全局状态。交易树只承诺当前区块中的交易列表。
Q8:收据和交易结果是不是等于状态变化?
不是。收据记录执行结果、gas 和日志。状态变化体现在新的 stateRoot 中。
18. 易错点
不要把交易哈希说成交易树的 key。交易树 key 是交易在当前区块里的 index。
不要把收据树说成保存交易本身。收据树保存交易执行后的 receipt。
不要说 Bloom Filter “判断存在就一定存在”。它只能判断可能存在,仍需继续查 logs。
不要把 receiptsRoot 当成状态根。receiptsRoot 承诺执行结果记录,stateRoot 承诺执行后的世界状态。
不要把交易树和状态树的 MPT 必要性混为一谈。状态树更需要 MPT,交易树和收据树更多是工程统一。
19. 总结
交易树、收据树和状态树共同把以太坊区块执行过程固定下来。
交易树承诺输入:当前区块有哪些交易,以及顺序是什么。
收据树承诺输出记录:每笔交易执行后的状态码、gas、日志和日志过滤信息。
状态树承诺最终世界状态:所有交易执行完后账户与合约存储处于什么状态。
总结时,最好按“输入交易 -> 执行交易 -> 生成收据 -> 更新状态 -> 三个根写入区块头”这条线讲,逻辑最清楚。
- 标题: 以太坊交易树和收据树知识点
- 作者: Kylinxin
- 创建于 : 2026-06-04 09:17:00
- 更新于 : 2026-06-22 10:00:00
- 链接: https://kylinxin.github.io/2026/06/04/以太坊交易树和收据树知识点/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。