区块链技术与应用 16:ETH-状态树
ETH-状态树
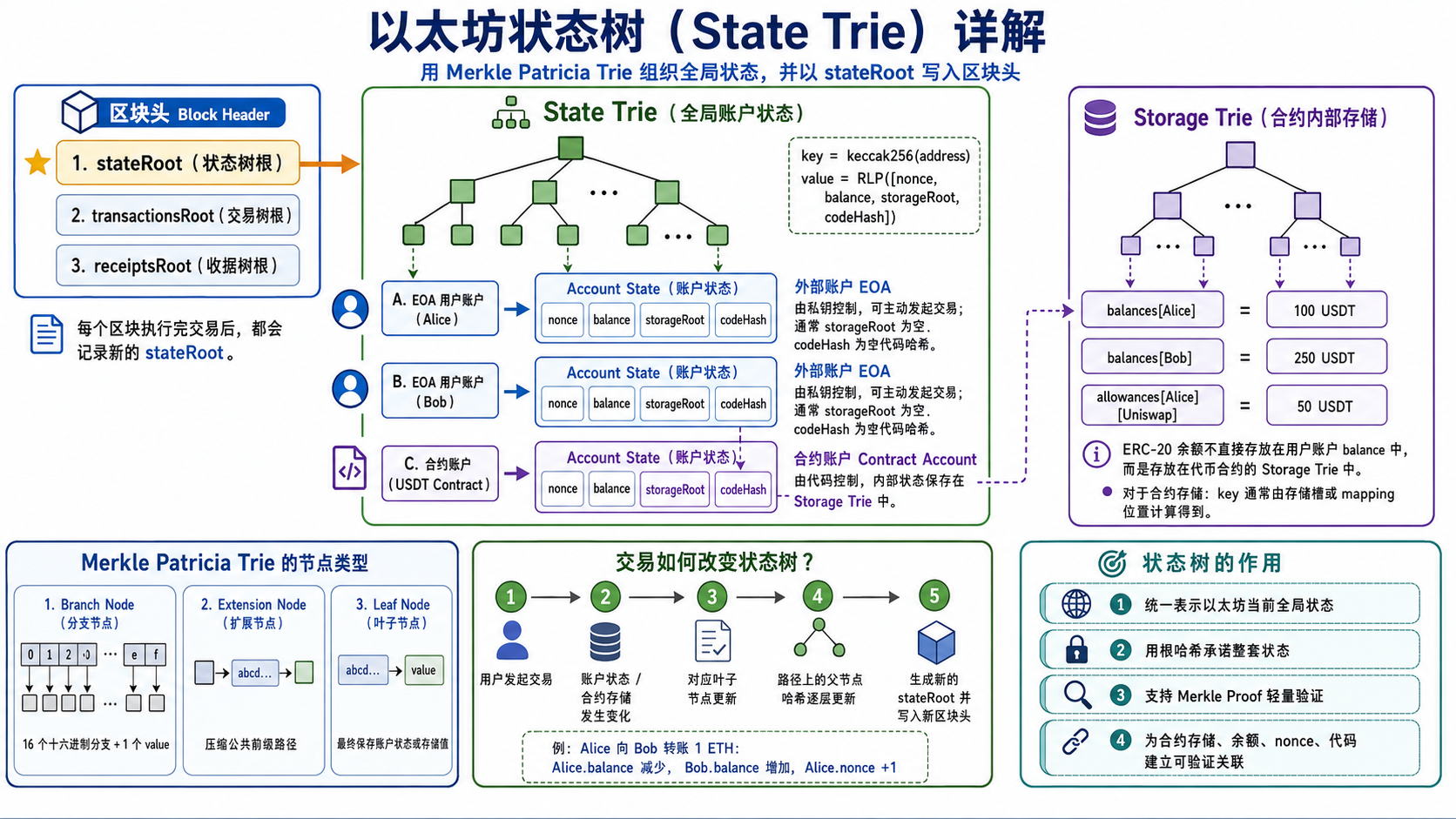
以太坊用 State Trie 记录所有账户的当前状态。每个账户状态包含 nonce、balance、storageRoot 和 codeHash。普通用户账户主要记录 ETH 余额和 nonce;合约账户还通过 storageRoot 连接到自己的 Storage Trie,用来保存合约变量,例如 ERC-20 余额。每次交易执行后,相关账户或合约存储发生变化,树上相关节点哈希逐层更新,最终生成新的 stateRoot,并写入新区块头。
1 | 交易执行→ 账户状态变化→ State Trie 更新→ stateRoot 改变→ 新区块头记录 stateRoot |
以太坊状态树与 Modified Merkle Patricia Trie 学习笔记
1. 以太坊为什么需要状态树
以太坊和比特币最大的区别之一在于账本模型不同。比特币主要使用 UTXO 模型,关注的是“哪些输出还没有被花费”;而以太坊采用账户模型,需要维护一个全局状态映射:
1 | address → account state |
也就是说,以太坊需要根据账户地址找到对应的账户状态。一个以太坊账户地址长度为 160 bit,也就是 20 字节,通常表示为 40 个十六进制字符,例如:
1 | 0x742d35Cc6634C0532925a3b844Bc454e4438f44e |
每个账户状态主要包括四个字段:
1 | nonce |
其中,nonce 用于记录账户交易次数或合约创建次数,balance 表示账户持有的 ETH 原生余额,storageRoot 指向合约账户的内部存储树,codeHash 表示合约代码的哈希。普通外部账户一般没有合约代码,也没有复杂存储;而智能合约账户则会通过 storageRoot 关联自己的合约存储。
因此,以太坊实际上需要维护的是一个巨大的、动态变化的全局状态数据库。每执行一笔交易,都可能改变账户余额、nonce 或合约内部变量。为了让所有节点能够验证自己维护的是同一份状态,以太坊不能只使用普通数据库结构,而需要一种既能高效查找,又能提供加密证明的数据结构。
2. 为什么不能只用哈希表
如果只从查找角度看,哈希表很适合维护:
1 | address → state |
例如:
1 | map[address] = accountState |
这样可以快速根据地址找到对应账户状态,平均查询复杂度接近 O(1)。但是普通哈希表不能满足区块链系统的核心要求。
首先,普通哈希表没有天然的全局根哈希。区块链需要让所有节点用一个简短的值证明“当前全局状态是否一致”。如果每个节点只是本地维护一个哈希表,那么很难用一个统一的哈希值来代表整套账户状态。
其次,普通哈希表不支持 Merkle Proof。假设轻节点想验证 Alice 的账户余额确实是 5 ETH,如果只有哈希表,完整节点只能直接告诉它结果,轻节点无法用一条短证明路径验证该状态是否真的属于某个区块的全局状态。
以太坊需要的是:
1 | 一个状态发生变化后,根哈希也随之变化; |
所以,普通哈希表虽然查找快,但不能提供状态承诺、轻量证明和全局一致性验证。
3. 为什么不能直接使用普通 Merkle Tree
普通 Merkle Tree 可以提供根哈希,也可以用于证明某个叶子是否属于这棵树。例如比特币区块中的交易 Merkle Tree,就是把当前区块里的交易按顺序组织起来,最终得到一个 Merkle Root。
但是,以太坊状态不是一个固定交易列表,而是一个动态的键值映射:
1 | address → account state |
普通 Merkle Tree 不适合直接维护这种结构,主要有三个问题。
第一,普通 Merkle Tree 本身不提供快速按 key 查找和更新的能力。它只知道叶子节点的位置,却不知道某个地址应该对应哪个叶子。如果要查询某个账户,还需要额外维护地址到叶子位置的索引。
第二,Merkle Tree 的根哈希依赖叶子节点顺序。如果不同全节点按照不同顺序组织账户叶子,即使包含的账户状态完全相同,最终得到的 root hash 也可能不同。区块链要求所有节点在相同状态下必须得到同一个根哈希,因此叶子顺序必须是确定的。
比特币中没有这个问题,是因为区块内交易顺序由出块节点确定,并写入区块,其他节点按同样顺序验证即可。而以太坊状态树维护的是全局账户映射,不是某个区块内的交易列表,因此不能依赖随机或本地顺序。
第三,如果使用 sorted Merkle Tree,也就是先按 key 排序再构建树,虽然可以解决顺序不一致的问题,但新增账户或新存储项时可能插入到叶子序列中间,导致大量叶子位置变化,进而引发大范围重构。
例如当前叶子 key 是:
1 | 10, 20, 30, 40 |
新加入一个 key:
1 | 25 |
它应该插入到 20 和 30 中间,叶子排列变成:
1 | 10, 20, 25, 30, 40 |
如果采用普通排序 Merkle Tree,后续分组和父节点结构可能发生较大变化,更新成本较高。因此,以太坊需要一种更适合动态键值映射的数据结构。
4. Trie、Patricia Trie 与稀疏地址空间
Trie,又称字典树或前缀树,它的特点是用 key 的每一位决定路径。比如 key 是:
1 | a7f3... |
那么查找路径就是:
1 | root → a → 7 → f → 3 → ... |
这种结构非常适合维护键值映射,因为 key 本身决定了存储位置,不需要额外排序,也不需要额外索引。对于以太坊来说,账户地址或地址哈希可以作为 key,账户状态作为 value。
但是普通 Trie 也有问题。如果 key 很长,而且很多路径没有分支,就会产生大量只有一个子节点的中间节点。例如只有一个 key:
1 | abcdef |
普通 Trie 可能会展开为:
1 | root → a → b → c → d → e → f → value |
这会浪费大量空间。
Patricia Trie 是压缩前缀树,它会把没有分叉的长路径压缩起来。例如:
1 | root → abcdef → value |
如果有两个 key:
1 | abcdef |
则可以压缩为:
1 | root |
以太坊地址空间非常稀疏。地址长度是 160 bit,理论地址数量是:
1 | 2^160 |
这是一个极大的空间,但真实存在的账户数量远远小于这个理论上限。如果使用普通 Trie,会有大量空路径和单支路径,因此更适合使用 Patricia Trie 进行路径压缩。
更准确地说,以太坊状态树通常使用的是地址的哈希值作为路径 key,例如:
1 | key = keccak256(address) |
这样可以让 key 分布更均匀,避免攻击者构造大量相似前缀地址导致树结构退化。虽然地址本身是 160 bit,但哈希后的路径空间更接近 256 bit,不过“极度稀疏”这一点仍然成立。
5. MPT:Merkle Patricia Trie
MPT 全称是 Merkle Patricia Trie,可以理解为:
1 | Merkle Tree + Patricia Trie |
它结合了两类能力。
Patricia Trie 提供的是高效的键值查找、插入、更新和路径压缩。Merkle 结构提供的是哈希承诺、防篡改能力和 Merkle Proof。
MPT 中每个节点都会参与哈希计算。如果某个账户状态发生变化,那么对应叶子节点的哈希会变化,父节点哈希也会变化,并一路影响到根节点,最终导致 stateRoot 改变。
例如,Alice 的余额从 5 ETH 变成 4 ETH:
1 | Alice.balance 变化 |
这意味着如果有人试图篡改账户状态,就无法得到与区块头中记录的 stateRoot 一致的结果。
MPT 还支持 Merkle Proof。轻节点不需要保存完整状态树,只要知道区块头中的 stateRoot,再获得从根到目标账户叶子的证明路径,就可以验证某个账户状态是否真实存在于该状态树中。
MPT 也可以用于证明某个账户不存在。因为 Trie 的路径由 key 决定,如果查找路径中某个分支不存在,或者最终叶子路径不匹配,就可以证明对应 key 不在树中。
6. 以太坊使用的是 Modified MPT
以太坊实际使用的是 Modified Merkle Patricia Trie,即经过工程化修改的 MPT。这里的 “Modified” 主要体现在节点编码、路径编码、节点引用和存储优化等方面。
MPT 中主要有三类节点:
1 | Branch Node |
Branch Node 是分支节点。以太坊把 key 拆成十六进制 nibble,每一位可能是 0 到 f,所以分支节点最多有 16 个方向,此外还可以有一个 value 字段。
Extension Node 是扩展节点,用于压缩公共路径。例如多个 key 共享相同前缀时,可以把这段公共前缀压缩成一个节点。
Leaf Node 是叶子节点,最终保存账户状态或合约存储值。
以太坊还会对节点和值进行统一编码,常用编码方式是 RLP,即 Recursive Length Prefix。账户状态:
1 | [nonce, balance, storageRoot, codeHash] |
会先被 RLP 编码成字节序列:
1 | RLP([nonce, balance, storageRoot, codeHash]) |
然后作为状态树中的 value 进行存储和哈希计算。统一编码非常重要,因为哈希函数处理的是字节序列。如果不同节点对同一个账户状态采用不同编码方式,就会得到不同哈希,最终导致 stateRoot 不一致。
7. 状态树、存储树与账户状态
以太坊状态树维护的是全局账户状态:
1 | keccak256(address) → RLP(account state) |
其中 account state 包含:
1 | nonce |
对于普通外部账户 EOA,例如 Alice 或 Bob:
1 | Alice 地址 → Alice Account State |
其中主要有:
1 | nonce:交易计数 |
对于合约账户,例如 USDT 合约:
1 | USDT 合约地址 → USDT Account State |
其中 storageRoot 指向该合约自己的 Storage Trie,codeHash 表示合约代码哈希。
这说明 ERC-20 余额并不是直接存在用户账户的 balance 字段里。用户账户的 balance 只表示 ETH 原生余额,而 USDT、USDC 等 ERC-20 余额存在对应代币合约自己的存储树中。
例如:
1 | Alice 有 3 ETH |
两者存储位置不同:
1 | 3 ETH → Alice 账户状态中的 balance 字段 |
USDT 合约内部可能有:
1 | mapping(address => uint256) balances; |
对应到存储树中可以理解为:
1 | balances[Alice] = 100 USDT |
因此,以太坊的状态结构可以理解为“树中挂树”:
1 | Block Header |
8. 每个区块为什么会产生新的状态树
以太坊每个区块执行完交易后,都会得到一个新的状态根:
1 | Block 100 执行后:stateRoot = root_100 |
从逻辑上看,每个区块都对应一个新的世界状态版本,也可以理解为产生了一棵新的状态树。
但是,这并不意味着每个区块都完整复制一整棵 MPT。实际更像是一种持久化数据结构。新状态树和旧状态树共享大部分未改变的节点,只有发生变化的路径需要创建新节点。
例如 Alice 给 Bob 转 1 ETH。执行前:
1 | Alice.balance = 5 ETH |
执行后:
1 | Alice.balance = 4 ETH - gas |
这次交易只影响 Alice 和 Bob 的账户状态,因此只需要更新 Alice 和 Bob 对应路径上的节点。其他没有变化的账户和合约子树可以继续复用。
这类似于 Git 的 commit。一次 commit 不会复制整个项目所有文件,而是记录变化,并通过哈希对象复用未变化的内容。
9. 为什么不能原地修改状态树
以太坊不适合直接原地修改状态树,主要原因是区块链中临时性分叉很常见。
例如某一高度同时出现两个区块:
1 | Block 100 |
一部分节点先看到 101A,另一部分节点先看到 101B。后来其中一条分支成为规范链,另一条分支被丢弃。如果某个节点之前执行了 101B,而后来发现 101A 才是主链,就需要回滚 101B 的状态变化,再执行 101A。
如果状态是原地修改的,旧状态已经被覆盖,回滚会非常困难。而如果每个区块都有自己的 stateRoot,并且旧版本状态节点仍然可以被引用,那么节点就可以从错误分支切回正确分支。
此外,智能合约执行过程复杂,很多交易并不是简单可逆的。智能合约交易可能修改多个 storage slot,调用其他合约,依赖当前区块环境、价格预言机、合约内部状态等。交易执行后,仅根据新状态和交易内容,通常无法可靠反推出旧状态。
例如一个 DeFi 清算交易可能会:
1 | 读取用户抵押品 |
执行完成后,如果没有保存旧状态或变更日志,很难从新状态反推出执行前的所有旧值。因此,以太坊需要保留足够的历史状态信息,或者使用可共享旧节点的持久化结构来支持回滚和状态切换。
10. RLP 编码的作用
状态树中的 value 在存储前需要序列化。以太坊使用的序列化方式是 RLP,全称是:
1 | Recursive Length Prefix |
例如账户状态为:
1 | nonce = 1 |
它首先会被组织成列表:
1 | [1, 100, 0xabc..., 0xdef...] |
然后经过 RLP 编码变成确定的字节序列:
1 | RLP([1, 100, storageRoot, codeHash]) |
这个编码后的结果才会作为 MPT 中的 value 存储,并参与哈希计算。
RLP 的意义在于提供统一、确定的编码方式。因为不同节点必须对同一个账户状态计算出完全相同的字节表示,才能得到相同的哈希和相同的 stateRoot。如果编码规则不统一,即使账户状态内容一样,不同节点也可能得到不同的根哈希。
11. 用完整例子串联理解
假设当前状态中有三个账户:
1 | Alice: 5 ETH, nonce = 10 |
状态树中逻辑上保存:
1 | keccak256(Alice 地址) → RLP(Alice account state) |
当前区块头记录:
1 | stateRoot = root_100 |
现在 Alice 向 Bob 转账 1 ETH。交易执行后:
1 | Alice.balance = 4 ETH - gas |
于是 Alice 和 Bob 的账户状态发生变化,对应的叶子节点 value 发生变化,叶子节点哈希随之变化;然后路径上的父节点哈希逐层变化,最后整棵状态树的根哈希从:
1 | root_100 |
变成:
1 | root_101 |
新区块头记录新的:
1 | stateRoot = root_101 |
但是没有变化的账户,例如 Carol、USDT、Uniswap 等,它们对应的子树可以继续复用,不需要重新构建整棵树。
如果后来这个区块所在分支不是主链,节点可以回到旧的:
1 | root_100 |
再执行另一条分支上的区块。这就是状态树版本化和非原地修改的重要意义。
12. 总结
以太坊选择 Modified Merkle Patricia Trie,不是单纯为了存储数据,而是为了同时满足以下需求:
1 | 根据地址快速查找账户状态 |
普通哈希表虽然查找快,但不能提供全局根哈希和 Merkle Proof。普通 Merkle Tree 虽然能提供根哈希,但不适合动态的大规模键值映射。Sorted Merkle Tree 虽然能保证顺序一致,但新增节点可能导致较大范围重构。Trie 可以让 key 决定路径,Patricia Trie 可以压缩稀疏路径,Merkle 化之后又可以提供防篡改和证明能力。
因此,以太坊使用 Modified Merkle Patricia Trie 来维护全局状态。每个区块执行后都会产生新的 stateRoot,该根哈希写入区块头,用来承诺当前完整世界状态。新旧状态树共享大部分节点,只更新发生变化的路径,从而兼顾查找效率、状态证明、节点一致性和分叉回滚能力。