区块链技术与应用 17:ETH-交易树和收据树
ETH 交易树和收据树学习笔记
1. 交易树和收据树在区块中的位置
以太坊每个区块可以分为区块头和区块体。区块头中保存若干个根哈希,其中和本节内容相关的主要有:
1 | stateRoot |
它们分别对应:
1 | stateRoot → 状态树根,表示当前区块执行完成后的全局状态 |
可以这样理解:
1 | Block Header |
每个区块中有一组交易,交易被执行后会产生对应的收据。因此:
1 | 一笔交易 → 一个收据 |
如果当前区块中有三笔交易:
1 | Tx0 |
那么执行后也会有三个收据:
1 | Receipt0 |
交易树和收据树之间是一一对应关系:
1 | Tx0 → Receipt0 |
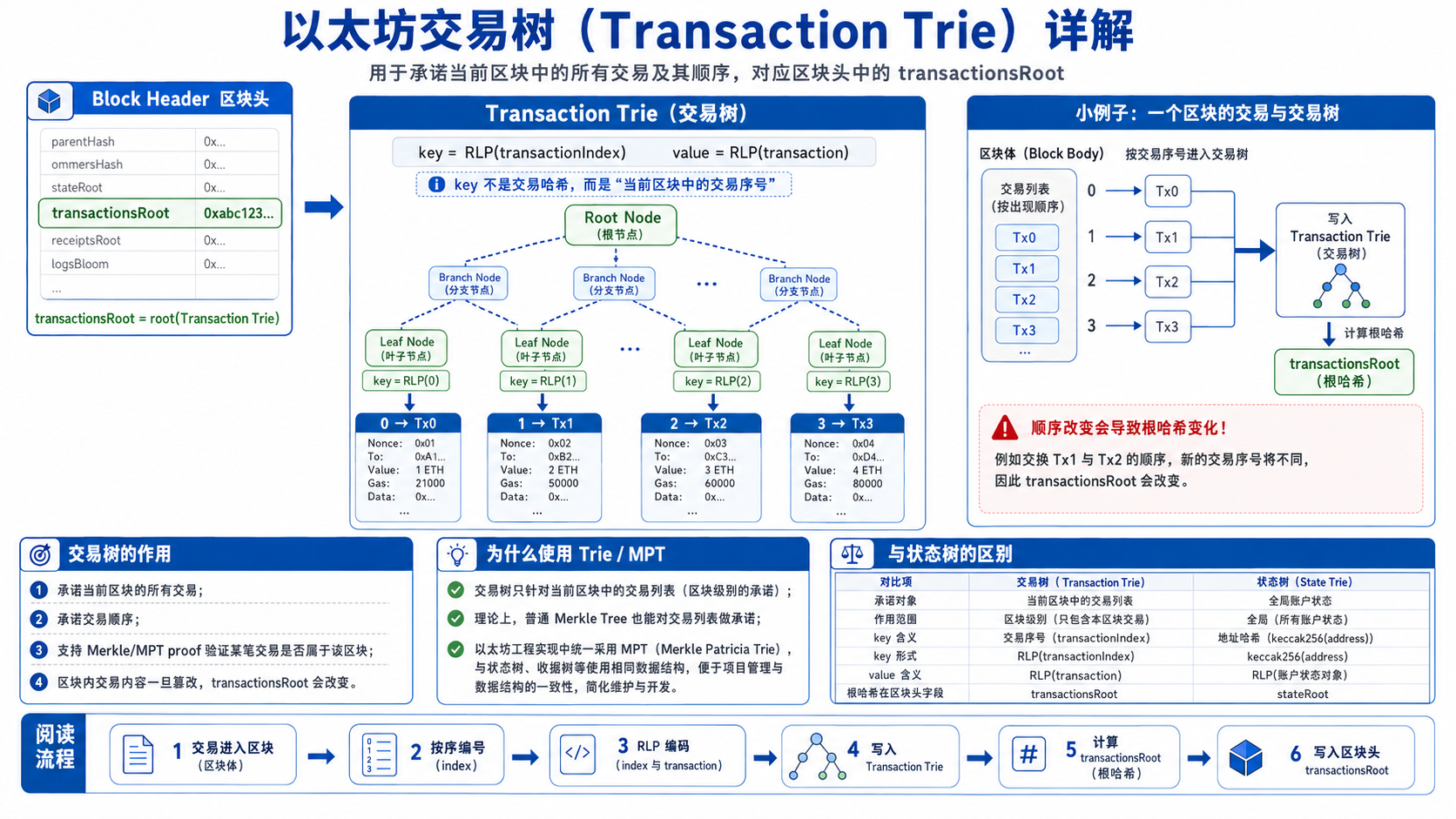
2. 交易树 Transaction Trie
交易树用于组织当前区块中的所有交易。它对应区块头中的:
1 | transactionsRoot |
交易树的作用是:
用一个根哈希承诺当前区块中包含的所有交易。
以太坊交易树的 key 不是交易哈希,而是交易在当前区块中的序号,也就是 transaction index。
逻辑上可以理解为:
1 | key = RLP(transactionIndex) |
例如某个区块中有三笔交易:
1 | 0 → Tx0 |
构建交易树后,区块头中保存:
1 | transactionsRoot = root(Transaction Trie) |
这样一来,只要区块中的任意一笔交易发生变化,或者交易顺序发生变化,最终得到的 transactionsRoot 都会改变。
这保证了两点:
1 | 1. 区块中的交易内容不能被篡改 |
交易顺序很重要,因为以太坊是状态机模型。交易执行顺序不同,可能导致最终状态不同。例如:
1 | Tx0:Alice 给 Bob 转 5 ETH |
如果交换顺序,Alice 的余额、nonce、合约执行结果都可能不同。因此,交易树不仅承诺交易内容,也间接承诺了当前区块的交易执行顺序。
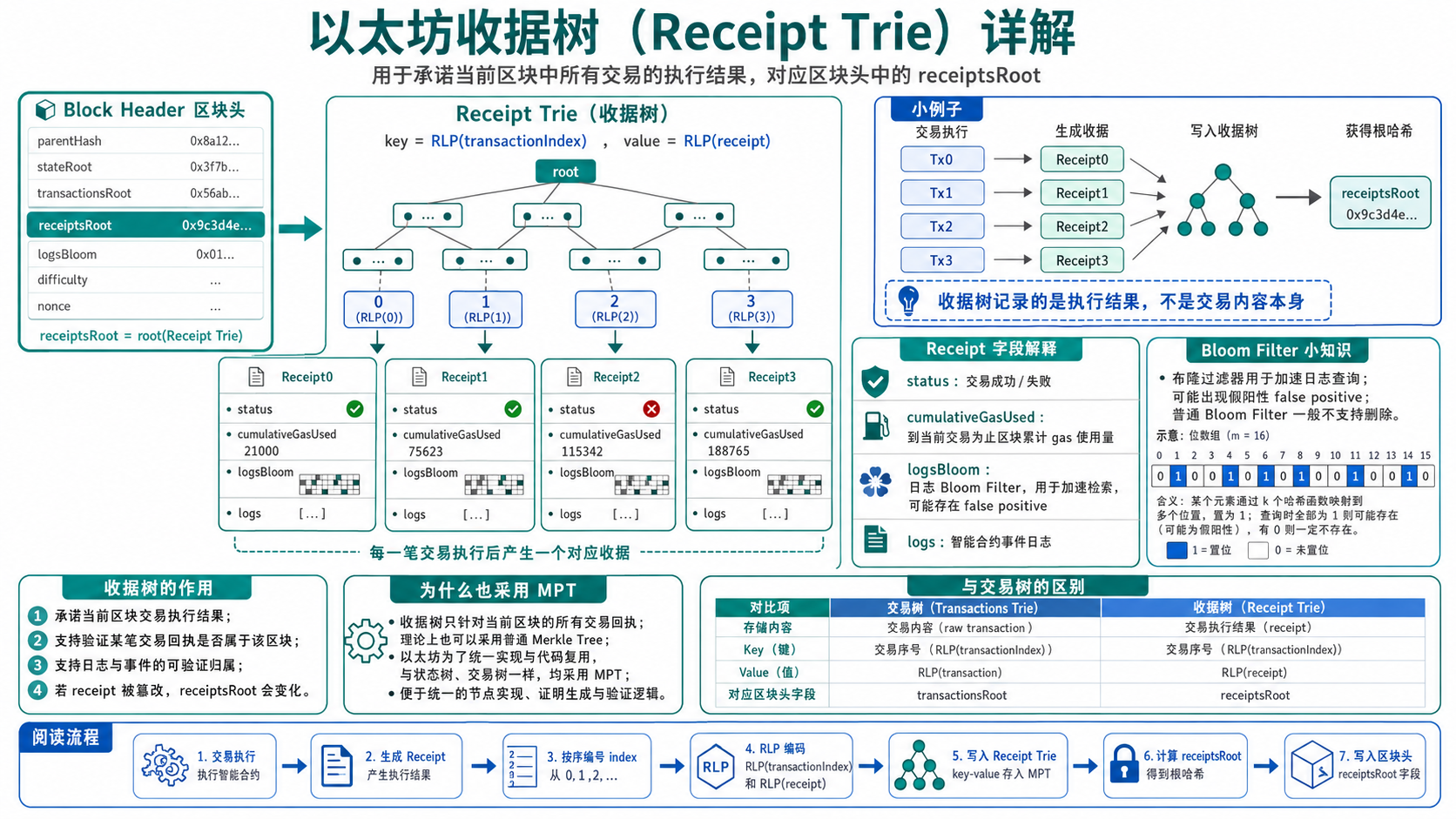
3. 收据树 Receipt Trie
收据树用于组织当前区块中所有交易执行后的结果。它对应区块头中的:
1 | receiptsRoot |
一笔交易执行完成后,会产生一个收据 Receipt。收据中通常包含:
1 | 交易执行状态 |
简化结构如下:
1 | Receipt |
其中:
1 | status → 交易是否成功,通常 1 表示成功,0 表示失败 |
收据树的 key 和交易树类似,也是交易在区块中的序号:
1 | key = RLP(transactionIndex) |
例如:
1 | 0 → Receipt0 |
对应:
1 | receiptsRoot = root(Receipt Trie) |
收据树的作用是:
用一个根哈希承诺当前区块中所有交易的执行结果。
如果有人修改某笔交易的执行状态、gas 使用量或事件日志,那么对应收据会变化,收据树根 receiptsRoot 也会变化,从而无法匹配区块头。
4. 交易树和收据树为什么也使用 MPT
以太坊中的状态树、交易树、收据树都可以用 MPT,即 Merkle Patricia Trie 来组织。
不过它们的使用场景不完全相同。
状态树是全局的、长期存在的、动态更新的结构。它维护的是:
1 | address → account state |
状态树需要支持大规模账户的查找、更新、证明、回滚等操作,因此使用 MPT 非常必要。
交易树和收据树则不同。它们都是针对单个区块构建的临时性数据结构:
1 | Transaction Trie:只组织当前区块中的交易 |
由于每个区块中的交易数量有限,而且 key 是连续的交易序号,所以从理论上说,交易树和收据树并不一定必须使用 MPT。它们也可以使用普通 Merkle Tree 来完成承诺和证明功能。
例如对于交易树来说:
1 | Tx0, Tx1, Tx2, Tx3 |
直接构建普通 Merkle Tree 也可以得到一个交易根,用于证明某笔交易属于当前区块。
但是以太坊统一使用 Trie/MPT 风格的数据结构,有利于工程实现和项目管理。这样状态、交易、收据都可以使用类似的 trie 数据结构、编码方式和根哈希计算方式。
因此可以总结为:
1 | 状态树使用 MPT:非常必要,因为它是全局动态键值状态 |
5. 交易树、收据树与状态树的区别
这三棵树虽然都和区块头中的根哈希有关,但含义不同。
| 树 | 对应根 | 范围 | key | value | 是否跨区块持续更新 |
|---|---|---|---|---|---|
| 状态树 | stateRoot | 全局账户状态 | keccak256(address) | RLP(account state) | 是 |
| 交易树 | transactionsRoot | 当前区块交易 | RLP(txIndex) | RLP(transaction) | 否 |
| 收据树 | receiptsRoot | 当前区块收据 | RLP(txIndex) | RLP(receipt) | 否 |
状态树反映的是:
1 | 当前整个以太坊执行后的世界状态 |
交易树反映的是:
1 | 当前区块里有哪些交易,以及交易顺序是什么 |
收据树反映的是:
1 | 当前区块里这些交易执行后产生了什么结果 |
交易树和收据树只属于当前区块,不是跨区块不断更新的全局结构。状态树则不同,它表示区块执行完成后的全局状态版本。
6. 收据中的日志与事件
智能合约执行过程中可以产生事件日志。例如 ERC-20 转账时通常会产生:
1 | event Transfer(address indexed from, address indexed to, uint256 value); |
当用户进行一次 USDT 转账后,合约可能会产生一条 Transfer 日志。日志一般包括:
1 | Address:产生日志的合约地址 |
可以理解为:
1 | Log |
这些日志会被放入对应交易的 Receipt 中。也就是说,用户在区块浏览器里看到的 ERC-20 转账记录,很多时候就是通过交易收据中的 logs 解析出来的。
因此,收据树不仅证明交易执行是否成功,还能证明某些事件日志确实由某笔交易产生,并被记录在某个区块中。
7. Bloom Filter 布隆过滤器
以太坊引入 Bloom Filter,主要是为了提高日志查询效率。
如果没有 Bloom Filter,当用户想查询某个合约地址或某个事件时,节点可能需要遍历大量区块和交易收据,逐个检查 logs。这样效率很低。
Bloom Filter 是一种空间效率很高的概率型数据结构,用于快速判断:
1 | 某个元素是否可能存在于集合中 |
它的特点是:
1 | 如果判断为不存在,则一定不存在 |
也就是说,Bloom Filter 可能出现 false positive,即假阳性。
例如查询某个事件是否出现在某个区块中:
1 | Bloom Filter 返回不存在 → 该事件一定不在这个区块 |
假阳性表示:
1 | Bloom Filter 说可能存在,但实际检查 logs 后发现不存在 |
但是 Bloom Filter 不会出现 false negative。也就是说,如果某个元素真的存在,Bloom Filter 不会说它不存在。
以太坊中 Bloom Filter 的意义是:
快速过滤掉大量明显不相关的区块或收据,只对可能相关的数据进行进一步检查。
这可以显著提高事件日志查询速度。
8. Bloom Filter 为什么一般不支持删除
普通 Bloom Filter 的底层通常是一个 bit array。插入元素时,会通过多个哈希函数计算出多个位置,并把这些位置置为 1。
例如插入元素 A:
1 | hash1(A) → 位置 3 |
于是:
1 | bit[3] = 1 |
但是多个元素可能会共享某些 bit 位。
例如元素 B 也可能设置:
1 | bit[8] = 1 |
如果现在要删除 A,不能直接把 bit[8] 置为 0,因为这个位置可能也是 B 需要的。如果直接清零,就会导致 B 被误判为不存在,从而出现 false negative。
所以普通 Bloom Filter 不支持安全删除。
如果需要支持删除,可以使用 Counting Bloom Filter。它不是用 bit,而是用计数器:
1 | 插入元素 → 对应计数器 +1 |
但这样会增加存储成本和实现复杂度。
9. 以太坊是交易驱动的状态机
以太坊可以看作一个交易驱动的状态机。
它的基本模型是:
1 | 旧状态 + 交易 → 新状态 |
更具体地说:
1 | State_N + Block_N 中的交易序列 → State_N+1 |
每个区块中的交易按照确定顺序执行。执行完成后,得到新的全局状态树根:
1 | stateRoot |
可以表示为:
1 | S_{t+1} = Apply(Tx_1, Tx_2, ..., Tx_n, S_t) |
这意味着,只要所有节点从相同的前置状态开始,并按照相同顺序执行相同交易,就必须得到完全相同的新状态和相同的 stateRoot。
这要求状态转移必须是确定性的。
10. 什么叫状态转移确定性
状态转移确定性是区块链共识的基本要求。
所谓确定性,就是:
所有节点执行同一笔交易,必须得到同样结果。
如果交易执行依赖不确定因素,就会导致不同节点计算结果不同,进而无法达成共识。
例如,智能合约不能直接调用普通互联网 API:
1 | 获取当前天气 |
因为不同节点在不同时间、不同网络环境下可能得到不同结果。
以太坊中合约能访问的是链上确定性数据,例如:
1 | 账户余额 |
即使是区块时间戳,也必须由区块生产者写入并被其他节点验证,而不是每个节点自己取本地系统时间。
因此,以太坊状态机的核心原则是:
1 | 相同输入 |
11. BTC 也可以看作状态机吗
可以。
虽然比特币通常被描述为 UTXO 模型,但它也可以被抽象为状态机。
比特币的状态可以理解为:
1 | 当前所有未花费交易输出集合,即 UTXO Set |
每一笔交易都会消耗一些旧 UTXO,并生成一些新 UTXO。
例如:
1 | 旧状态: |
所以 BTC 也可以表示为:
1 | UTXO Set_old + Transaction → UTXO Set_new |
只不过比特币的状态主要是 UTXO 集合,而以太坊的状态更复杂,包括账户余额、nonce、合约代码和合约存储。
因此:
1 | BTC 是 UTXO 状态机 |
12. 问题:每个区块只维护当前区块用到的交易账户状态是否可行
这个想法可以描述为:
不维护一个全局状态树,而是在每个区块中只保存当前区块交易涉及到的账户状态。
例如某个区块中只涉及 Alice、Bob 和 USDT 合约,那么这个区块只保存:
1 | Alice state |
表面看这样可以节省空间,因为每个区块不用保存完整状态树。但是这个方案在以太坊中不可行,或者至少非常低效。
主要问题是:查找账户当前状态会变得非常困难。
13. 为什么只保存局部状态会导致查询困难
假设你想查询 Alice 当前余额。如果每个区块只保存当前区块用到的账户状态,那么你需要从最新区块开始向前找:
1 | Block 1000:是否包含 Alice 状态? |
如果 Alice 很久没有交易,就可能要追溯很多区块,甚至一直追溯到创世区块。
这种查询成本非常高。
而以太坊的状态树设计是:
1 | 每个区块的 stateRoot 都承诺该区块执行后的完整全局状态 |
因此,只要拿到某个区块对应的状态树,就可以直接查询任意账户在该区块后的状态。
这就是全局状态树的意义。
14. 不存在账户的问题
你笔记中提到:
如果转账账户是一个不存在的区块就需要一直追溯到 Genesis 创世区块。
这里可以进一步解释。
如果每个区块只保存局部状态,当我们想判断某个账户是否存在时,就不能只看当前区块。因为当前区块没有出现该账户,可能有两种情况:
1 | 1. 这个账户真的不存在 |
为了区分这两种情况,节点必须一直向前追溯,寻找这个账户最后一次出现的位置。如果一直追溯到创世区块都没有出现,才能确认它不存在。
这显然非常低效。
而全局状态树支持不存在性证明。通过 State Trie 的路径,可以证明某个地址在当前状态树中没有对应账户,不需要从当前区块一路追溯到创世区块。
15. 为什么不能只保存“交易涉及账户的状态差分”
另一种想法是:每个区块只保存状态差分,也就是只保存变化的账户状态。
例如:
1 | Block N |
这种方式可以用于辅助回滚或历史追踪,但不能替代全局状态树。
原因是状态差分只能告诉你当前区块改了什么,却不能直接告诉你某个账户的当前完整状态。如果要查询一个很久没有变化的账户,仍然需要向前追溯它最后一次变化的位置。
而以太坊需要节点能够高效验证交易。例如,Alice 发起一笔交易时,节点必须快速检查:
1 | Alice 是否存在 |
如果没有全局状态树,就无法高效完成这些验证。
16. 为什么以太坊状态树必须是全局的
以太坊状态树的设计目标是:
1 | 任意时刻都能根据 stateRoot 表示完整世界状态 |
这有几个重要作用:
1 | 1. 快速验证新交易 |
如果只保存局部状态,这些能力都会受到影响。
因此,每个区块中的 stateRoot 不是只承诺当前区块涉及的账户,而是承诺当前区块执行完成后的完整全局状态。
注意,这并不意味着每个区块都完整复制一份状态树。以太坊状态树是持久化结构,新旧状态树可以共享大部分未变化节点。只有发生变化的路径需要更新。
17. 三棵树的整体关系
可以把以太坊区块理解为:
1 | Block N |
其中:
1 | transactionsRoot |
交易执行过程可以理解为:
1 | 1. 节点读取区块中的交易列表 |
18. 总结
交易树和收据树都是针对当前区块构建的数据结构。交易树用来承诺当前区块中的交易内容和顺序,收据树用来承诺这些交易执行后的结果。每一笔交易都会产生一个对应的收据,因此交易树和收据树在索引上是一一对应的。
以太坊中交易树和收据树也采用 MPT,这在工程上有利于统一数据结构和编码方式。由于它们只针对当前区块构建,理论上也可以使用普通 Merkle Tree;真正必须使用 MPT 的主要是状态树,因为状态树维护的是全局动态账户状态。
Bloom Filter 用于加速日志查询。它可以快速判断某个事件或地址是否可能出现在某些日志中。Bloom Filter 的特点是可能出现假阳性,但不会出现假阴性;普通 Bloom Filter 不支持删除,因为多个元素可能共享同一个 bit 位。
以太坊可以看作交易驱动的状态机。每个区块中的交易按确定顺序执行,从旧状态转移到新状态。所有节点必须在相同输入、相同前置状态和相同执行规则下得到相同结果,否则无法达成共识。比特币也可以被抽象为状态机,只不过它的状态是 UTXO Set,而以太坊的状态是账户、合约代码和合约存储组成的世界状态。
“每个区块只保存当前区块用到的账户状态”这个方案并不可行。它会导致账户查询、余额验证和不存在性证明都变得困难。如果某个账户很久没有交易,节点可能需要一直向前追溯到创世区块才能确认它的状态。以太坊使用全局状态树,就是为了让每个区块的 stateRoot 都能承诺当前完整世界状态,同时通过 MPT 的节点共享机制避免完整复制整棵状态树。